高级程序员知识学习——mybatis的学习
本文共 947 字,大约阅读时间需要 3 分钟。
Mybatis是什么?
MyBatis 是一款优秀的持久层框架,它支持自定义 SQL、存储过程以及高级映射。MyBatis 免除了几乎所有的 JDBC 代码以及设置参数和获取结果集的工作。MyBatis 可以通过简单的 XML 或注解来配置和映射原始类型、接口和 Java POJO(Plain Old Java Objects,普通老式 Java 对象)为数据库中的记录。
传统的JDBC的缺点是:
1、数据库连接创建、释放频繁造成系统资源浪费,影响系统性能,可使用数据库连接池解决此问题。
2、sql语句中在代码中硬编码,代码不易维护,sql变动需要改变java代码。 3、使用preparedStatement向占有位符号传参数存在硬编码。where条件不一定,修改sql就要修改代码,不易于维护。 4、对结果集解析存在硬编码,sql变化导致解析代码变化,可封装成实体对象解析解决此问题。Mybatis底层原理实现?
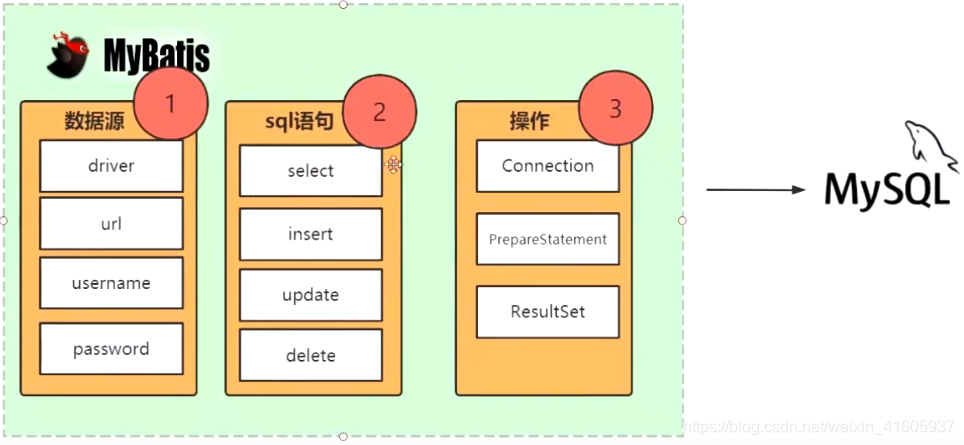
Mybatis是如何获取数据库的源?
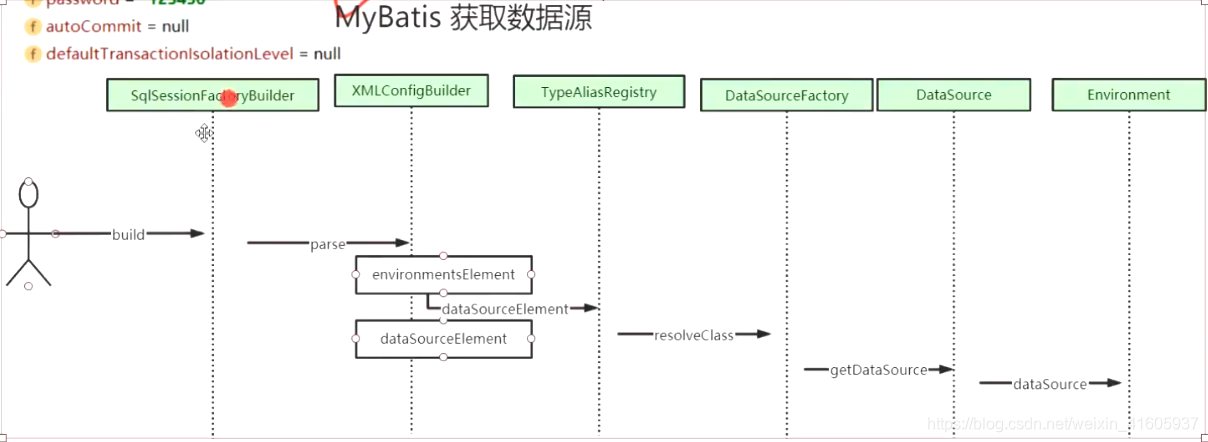
Mybatis是如何获取SQL?
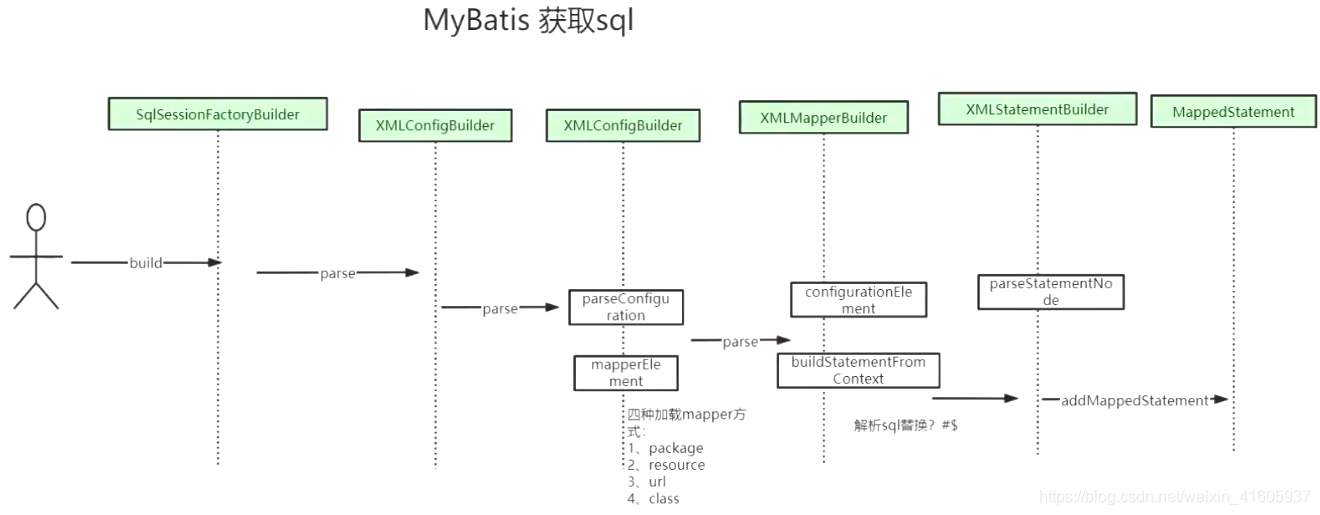
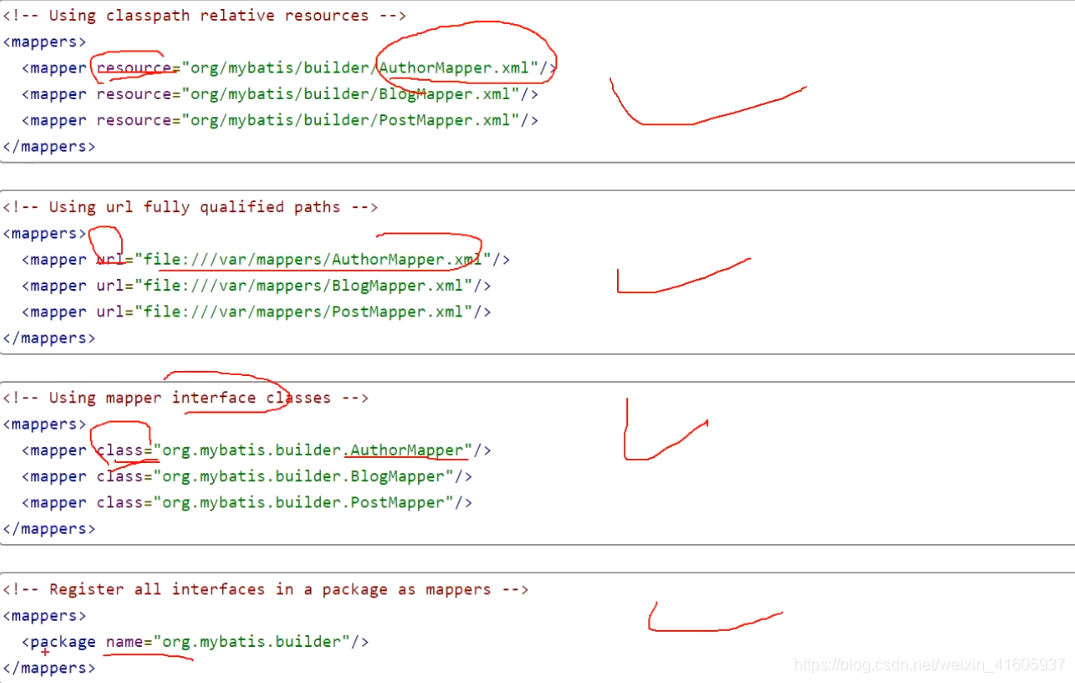
mapper的文件的加载有几种方式:
Mybatis的构建者模式:
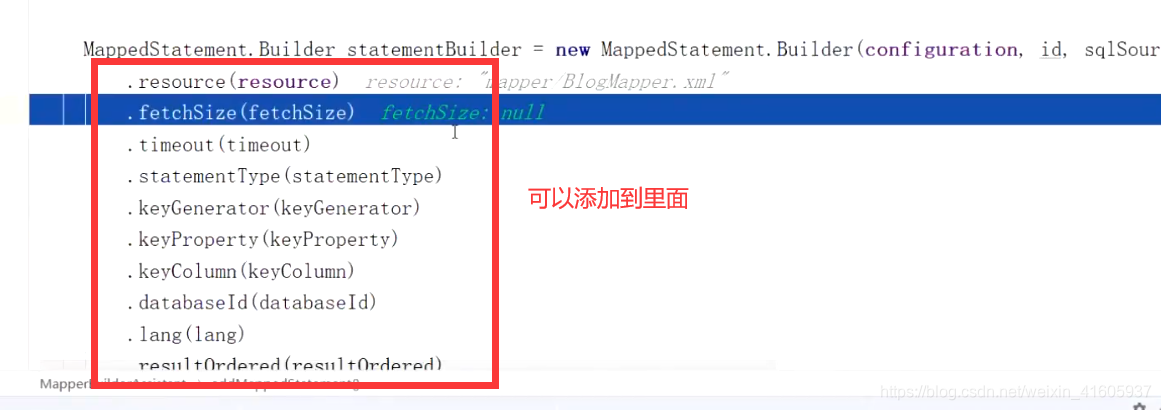
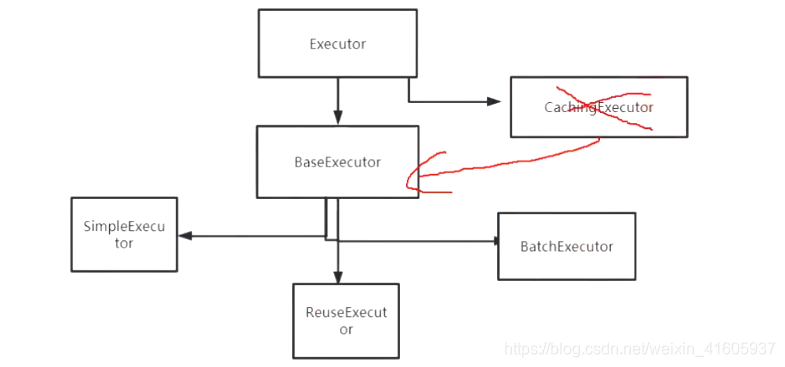
Mybatis是如何获取操作?
执行器: simple reuse batch
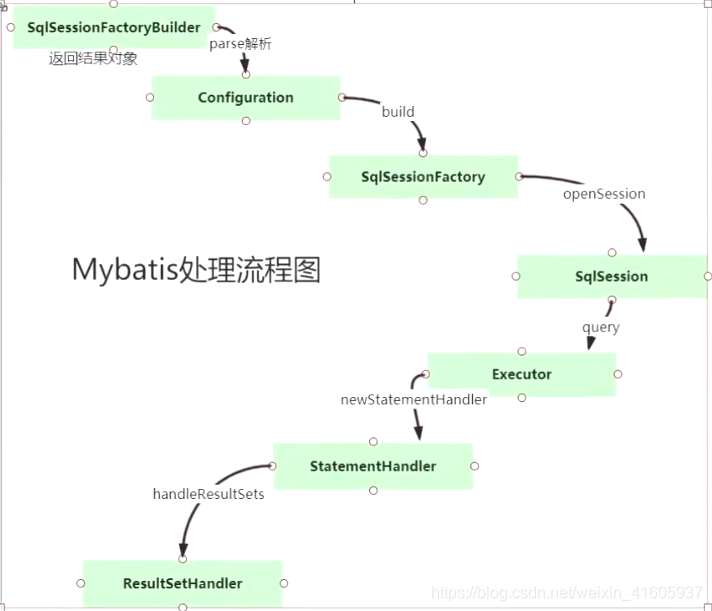
A系统怎么B系统怎么验证是否传过来的正确SQL的语句?
采用的的是SQL的解析器的就可以验证是否正确。
Mybatis中的装饰器的模式的体现

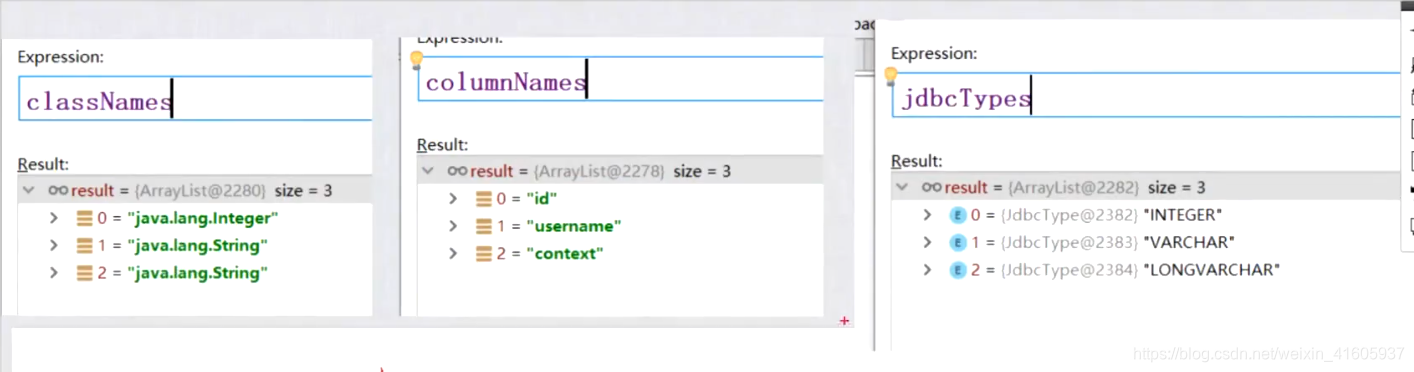
Mybatis是Select源码解析?
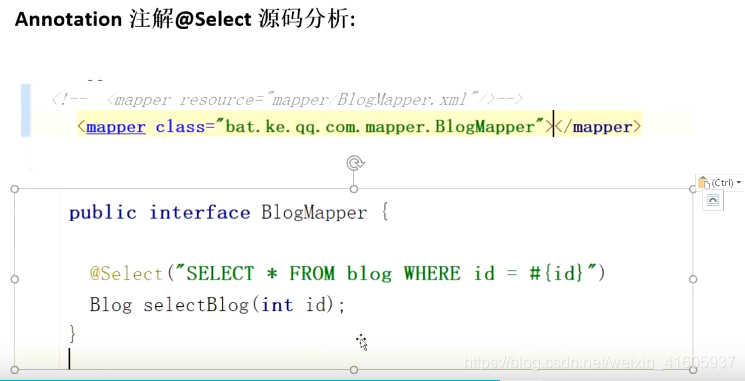
Mybatis先解析是XMl还是的解析注解?

Mybatis自带的selectone和Sqlseiion的selectone的方法的区别?
java的动态代理是是实现innvocationhandler的接口来实现的动态代理的一种的。实现invoke()的方法来实现的。
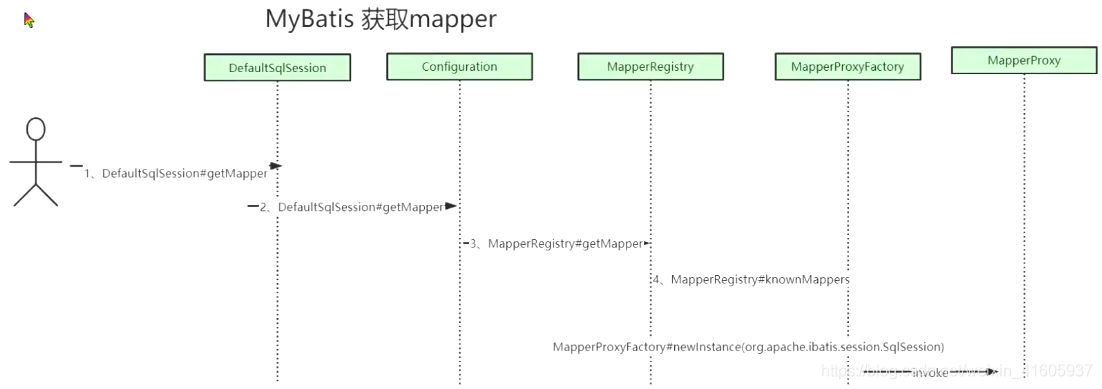
Mybatis的全局配置缓存执行器的原理
分页、监控、日志、 记录SQL、 数据埋点
利用的mybatis来查询的最慢的10条语句?
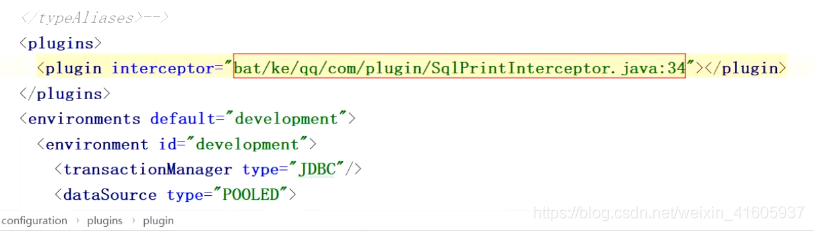
mybatis的plugin的原理解析:

Mybatis的#和$的区别?
#{}是经过预编译的,是安全的。而${}是未经过预编译的,仅仅是取变量的值,是非安全的,存在SQL注入。
#{} 这种取值是编译好SQL语句再取值${} 这种是取值以后再去编译SQL语句
转载地址:http://jach.baihongyu.com/
你可能感兴趣的文章
MFC模态对话框和非模态对话框
查看>>
Moment.js常见用法总结
查看>>
MongoDB出现Error parsing command line: unrecognised option ‘--fork‘ 的解决方法
查看>>
mxGraph改变图形大小重置overlay位置
查看>>
MongoDB可视化客户端管理工具之NoSQLbooster4mongo
查看>>
Mongodb学习总结(1)——常用NoSql数据库比较
查看>>
MongoDB学习笔记(8)--索引及优化索引
查看>>
mongodb定时备份数据库
查看>>
mppt算法详解-ChatGPT4o作答
查看>>
mpvue的使用(一)必要的开发环境
查看>>
MQ 重复消费如何解决?
查看>>
mqtt broker服务端
查看>>
MQTT 保留消息
查看>>
MQTT 持久会话与 Clean Session 详解
查看>>
MQTT工作笔记0007---剩余长度
查看>>
MQTT工作笔记0009---订阅主题和订阅确认
查看>>
Mqtt搭建代理服务器进行通信-浅析
查看>>
MS Edge浏览器“STATUS_INVALID_IMAGE_HASH“兼容性问题
查看>>
ms sql server 2008 sp2更新异常
查看>>
MS UC 2013-0-Prepare Tool
查看>>